UPDATE 쿼리 실행 시 WHERE 절을 PK로 지정해야 하는 이유
대부분의 데이터베이스에서 특정 row의 데이터를 변경하기 위해 UPDATE ... SET .. WHERE ... 쿼리를 이용하여 데이터를 변경합니다.
WHERE 절에는 row가 특정될 만한 조건을 넣어야 하는데, PK(Primary Key)를 조건으로 지정하는 것이 일반적입니다.
오래된 코드에서는 개발자의 성향이나 편의 등의 사유로 WHERE 절에 PK가 아닌 컬럼을 조건으로 지정하는 경우를 종종 볼 수 있습니다.
예를 들어 아래와 같은 데이터가 있다고 가정해 보겠습니다.
id는 PK로 지정되어 있고, 나머지 컬럼은 모두 index가 생성되어 있다고 전제하겠습니다.
| id | code | category_id | name | origin |
|---|---|---|---|---|
| 200 | P202309261343597462 | 3 | Audra Kuhn | soluta |
| 153 | P202309261343597056 | 3 | Orlando Sipes | recusandae |
| 146 | P202309261343591320 | 3 | Brett Davis PhD | quia |
| 106 | P202309261343583007 | 3 | Orlando Shanahan | sed |
| 48 | P202309261343585376 | 3 | Larry Boyer | quidem |
| 38 | P202309261343573938 | 3 | Mossie Schumm | dolore |
| 31 | P202309261343575130 | 3 | Una Parisian | consequatur |
id 값이 146인 row의 name을 변경하려면 아래와 같이 SQL을 작성합니다
UPDATE tbl_name SET name = 'New Product' WHERE id = 146
아래와 같이 쿼리를 작성해도 동일한 결과를 얻을 수 있습니다.
UPDATE tbl_name SET name = 'New Product' WHERE category_id = 3 AND origin = 'quia'
첫 번째 쿼리와 두 번째 쿼리 모두 변경하고자 하는 row 만 제대로 특정된다면 크게 문제는 없어 보이는데요,
그럼에도 불구하고 두 번째 쿼리보다 첫 번째 쿼리를 사용하는 것이 좋은 이유는 무엇일까요?
바로 PK와 PK가 아닌 컬럼의 인덱스가 서로 다른 방식이기 때문입니다.
MySQL 기준, 테이블에 부여할 수 있는 인덱스의 종류로는 Clustered Index와 Non-Clustered Index 가 있습니다.
Clustered Index의 특징은 아래와 같습니다.
- 테이블당 1개만 지정 가능
- Primary Key 또는 Unique Index만 지정 가능하며, Primary Key가 있는 경우 PK가, 없는 경우 Unique Index가 Clustered Index 로 지정됨
- 물리적인 정렬 방식을 이용하여 SELECT 속도가 빠름 (UPDATE/INSERT/DELETE 속도는 느림)
- 생성시 데이터 재정렬이 필요하여 큰 부하 발생
반면에 Non-Clustered Index의 특징은 아래와 같습니다.
- 테이블당 여러개 지정 가능
- 페이지 단위로 인덱스가 저장되며, 랜덤한 순서로 저장 (뒤죽박죽)
- SELECT 속도보다 UPDATE/INSERT/DELETE 속도가 빠름
- 생성시 부하가 적어 비교적 부담 없이 생성 가능
트랜잭션 구간 내에서 UPDATE 쿼리 실행시 데이터베이스는 WHERE 절을 기준으로 레코드에 lock을 걸어 다른 트랜잭션에 의해 데이터가 오염되지 않도록 방지합니다.
Clustered Index를 기준으로 WHERE 절을 지정하면 단일 row만 lock이 걸리지만, Non-Clustered Index를 기준으로 WHERE 절을 지정하면 모든 WHERE 조건을 만족하는 1개 row만 lock이 걸리는게 아니라 WHERE 절의 첫 번째 조건을 만족하는 row 중 나머지 조건이 일치하는 row가 속한 인덱스 페이지 단위로 lock이 걸리게 됩니다.
아래는 Non-Clustered Index의 구조를 설명한 그림입니다.
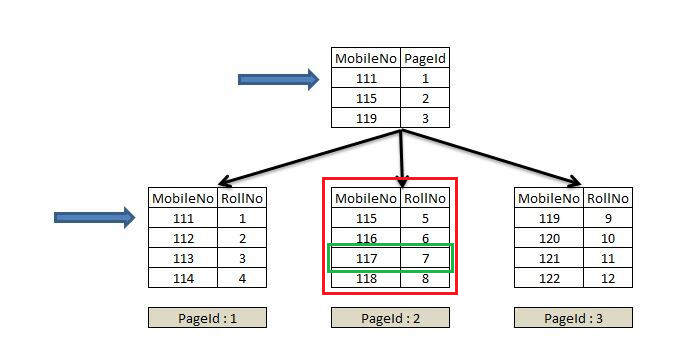
MobileNo = 117인 row를 변경하려고 시도한다면, MobileNo = 117인 row 1개만 lock 이 걸리는 것이 아니라, 같은 인덱스 페이지인 115 ~ 118 범위의 row가 모두 lock이 걸리게 됩니다.
즉, 아래 쿼리로 UPDATE를 시도한다면, id = 146 인 row 1개만 lock이 걸리는 것이 아닌, category_id = 3인 row 중 랜덤한 row들이 lock이 걸리게 됩니다. (인덱스내 row는 정렬이 랜덤이라 페이지별 범위가 특정되지 않습니다)
UPDATE tbl_name SET name = 'New Product' WHERE category_id = 3 AND origin = 'quia'
실제로 변경하려는 row외 다른 row가 lock이 걸리는지 실험을 해보겠습니다.
DataGrip에서 Tx: Manual 로 설정 후 아래 쿼리를 실행하여 Lock을 겁니다.
SELECT * FROM products WHERE category_id = 3 AND origin = 'quia' FOR UPDATE
이 상태에서 id = 106 인 row의 데이터를 변경하려고 시도하면 Lock wait timeout exceeded 오류와 함께 변경에 실패하게 됩니다.
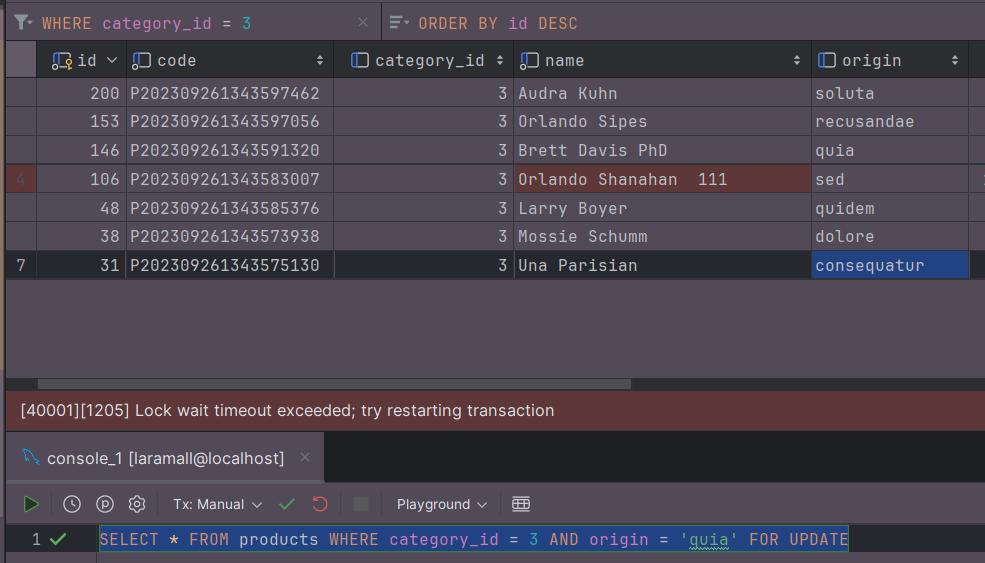
실제로 서비스중인 애플리케이션에 위와 같은 쿼리가 포함되었다면, Deadlock이 발생하여 전체 트랜잭션이 롤백되었을 것입니다. Non-Clustered Index 특성상 랜덤하게 페이지가 부여되기 때문에 항상 Deadlock이 발생하는 것이 아닌 '간헐적'으로 Deadlock이 발생하게 됩니다.
만약 운영중인 서비스에서 간헐적인 Deadlock이 발생하는데 원인파악이 어렵다면 위와 같은 케이스에 해당되지 않는지 면밀히 살펴보는 것이 좋습니다.
※ 본 포스팅을 할 수 있도록 조언과 도움을 아끼지 않았던 동료 개발자분께 감사드립니다.
PHP in_array() 내장함수 퍼포먼스 이슈
PHP 배열에서 특정값이 있는지 확인을 위해 아래와 같이 in_array() 내장함수를 많이 이용합니다.
<?php
$arr = [1, 3, 55, 88];
if (in_array(55, $arr)) { ... }
위 방식은 사용이 간편하지만 회사에서 대량의 데이터를 생성하는 배치를 개발하던 도중에 심각한 퍼포먼스 저하 현상을 겪었습니다.
특정 기간 내의 데이터를 조회하여 일/월별로 중복제거 또는 합산을 처리하는 코드를 작성 중이었는데, 중복제거를 위한 배열에 값을 넣어두고 루프를 돌 때마다 값이 있는지 확인하는 로직이었는데요,
in_array() 대신 아래와 같은 방식을 활용하여 퍼포먼스 개선을 할 수 있었습니다.
<?php
$arr = [
1 => true,
3 => true,
55 => true,
88 => true
];
if(isset($arr[55])) { ... }
위 현상에 대한 ChatGPT 답변은 아래와 같습니다.
|
두 코드 조각은 모두 주어진 배열에서 특정 요소가 존재하는지 확인하는 방법을 보여주고 있지만, 두 번째 코드 조각이 성능 면에서 더 효율적인 이유는 다음과 같습니다. 첫 번째 코드 조각에서 in_array 함수를 사용하면 배열을 순회하면서 특정 요소를 찾아야 합니다. 배열의 크기에 따라서 성능이 저하될 수 있습니다. 이 함수의 시간 복잡도는 O(n)입니다. 따라서 배열의 크기가 크면 성능 저하가 발생할 수 있습니다. 두 번째 코드 조각에서는 연관 배열(associative array)을 사용하여 각 요소를 키로 가지고 있는데, 이렇게 하면 배열 내에서 특정 요소를 바로 접근할 수 있습니다. 연관 배열에서 요소를 접근하는 시간 복잡도는 O(1)이므로 매우 빠릅니다. 따라서 특정 키의 값에 접근하는 작업은 상수 시간만큼 걸리며, 배열의 크기와 무관합니다. 따라서 두 번째 코드 조각은 특정 키의 값에 접근하는 과정에서 상대적으로 더 빠르며, 큰 배열에서도 성능을 유지할 가능성이 높습니다. 하지만 이러한 성능 차이는 배열의 크기와 사용하는 컴퓨터 환경에 따라 달라질 수 있으므로, 실제 사용 시에는 성능 테스트를 통해 확인하는 것이 좋습니다. |
NativePHP + Ubuntu 22.04 환경 오류
![]()
![]()
- PHP로 크로스 플랫폼 데스크탑 어플리케이션 작성
- OS 기능을 사용할 수 있게 해주는 클래스들 모음 + Electron 또는 Tauri + 스태틱 PHP 런타임
- 윈도우/메뉴/파일 관리
- DB(SQLite) 지원
- 네이티브 Notification
PHP로 데스크탑 어플리케이션을 개발할 수 있는 프레임워크가 출시되었다고 하길래, 냅다 설치해봤습니다.
현재 맥/우분투 환경만 지원하며, 맥 장비가 없는 관계로 우분투 22.04 환경에서 설치를 시도해봤습니다.
NativePHP는 단독으로 구성할 수 없으며, 사전에 Laravel 설치가 필요합니다.
아래와 같은 절차로 진행합니다.
$ composer create-project laravel/laravel test-app
$ cd test-app
$ composer require nativephp/electron
$ php artisan native:install
하지만, php artisan native:install 실행시 아래와 같은 오류가 발생합니다.
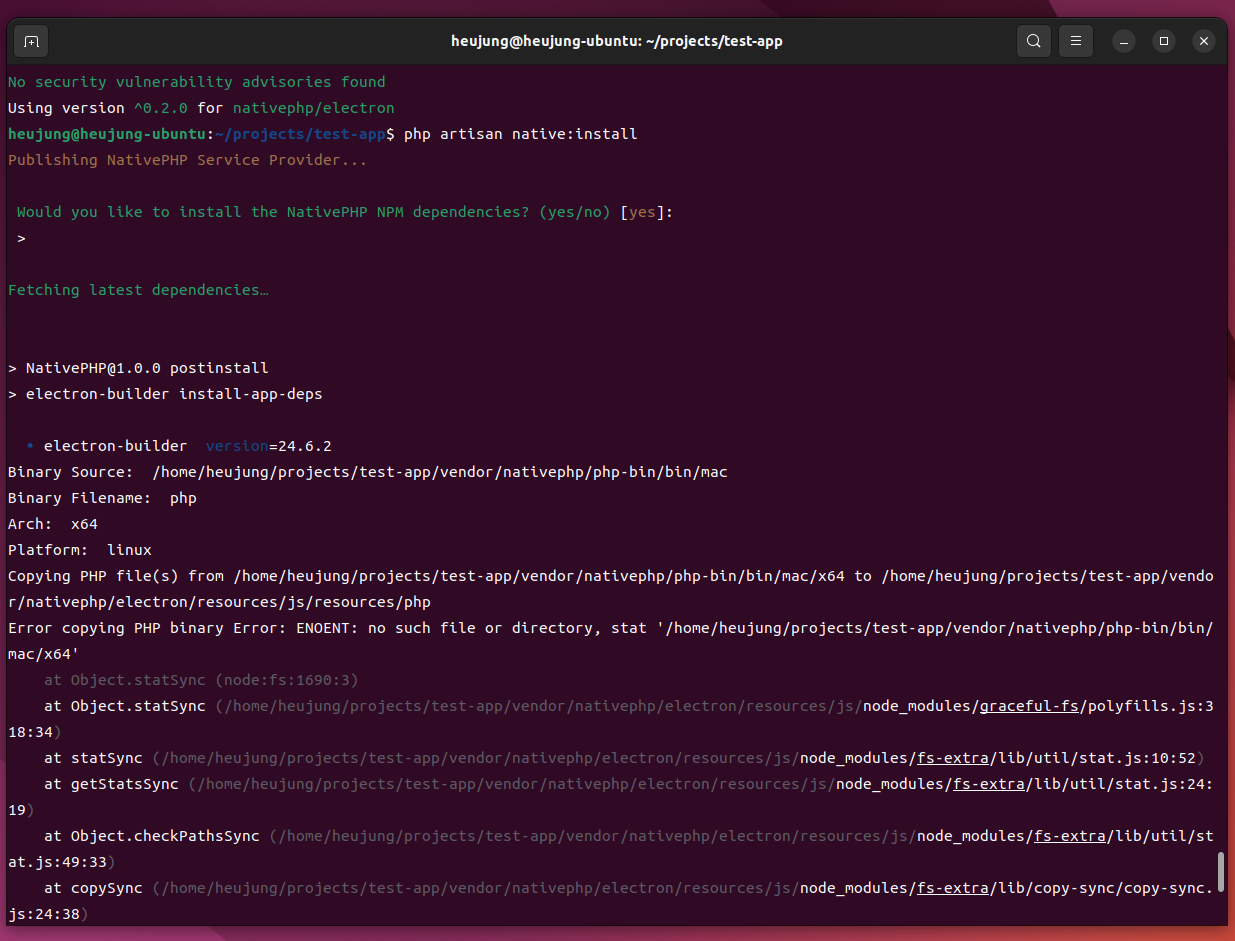
오류 내용으로 미루어 볼 때, 리눅스 환경임에도 불구하고 Mac용 PHP 바이너리를 참조하려고 시도하는것으로 보입니다.

해당 디렉토리에는 x64 디렉토리도 존재하지 않는것을 알 수 있습니다.
아직 우분투에서는 개발할 수 있는 환경이 갖추어지지 않은 것으로 보입니다.
나중에 Mac 장비를 구하게 되면 다시 시도해보거나, 우분투 대응 업데이트를 해주길 기다리는 방법밖에 없을듯 합니다.
Recent Comments